Deepak Kaushik (Microsoft Azure MVP)

When migrating into Azure you should consider few things that must define or result to a successful migration.
- Lower your TCO (Total Cost of Ownership) more than 60%
- Reduce Time to Market (Scope / Release an MVP (Minimum Viable Product))
- Hybrid environment
- Secure security for your hybrid environment (SSO=Single sign on, Azure IAM solution)
- Reuse/extend your on-premises licensing in Azure.
- Use the new features in each Azure service and optimize your data within the cloud.
Let’s mention some of the way in migrating your data into Azure.
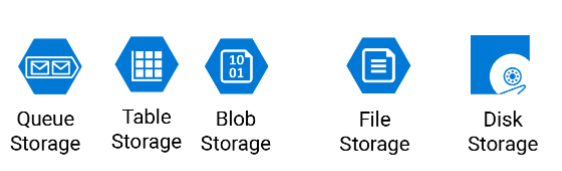
- Storage Services
Azure has numerous ways in storing your on-premises data, but the main question is what kind of data are they? Are they archive data, or transactional data? BI data? What format are they in? file/DB? How is the data moving around? Transactional/Incremental/… as you can see each set of data have a different nature that needs to be treated differently and for that Microsoft has a variety of Azure services as mentioned.
- Azure Blob Storage (Cold Storage) (Archiving data)
- Azure Blob Storage (Hot Storage) (Streaming data)
- Azure NetApps Files (File Storage)
- Azure SQL Database (Transactional database)
- Azure Cosmos DB (Geo distribution data)
- ● Azure Data base For PostgreSQL
- Azure Data base For MySQL
- … and many, many more.
- Transfer Services
One of the most famous services that migrates your on-premises data to the cloud is Azure Database Migration Services, this service can migrate any well knows database software/application to the Azure cloud, it also can migrate your data base in a offline or online approach (minimal downtime).

Also they are numerous ways in migrating to Azure using different services like..
- Azure Migrate: Server Migration
- Data Migration Assistant
- Azure Database Migration Service
- Web app migration assistant
- Azure Data Box
- Azure Data Factory
- Azure CLI (Command Line).
- Azure PowerShell.
- AZCopy utility
- Third part migration tools certified by Microsoft.
- On-prem tools, for example SSIS.


- Analytics and Big Data
The definition of Analytics in the data world is to have the analytics team deal with the entire data, that leads them in dealing with big data and running/process/profiling massive amount of data and for that Microsoft have provided a variety of tools depending on the analytics team needs, or the type/volume of data, some of the most well knows analytics tools within the azure are as mentioned and some of them have embedded internal ETL tools.
- Azure Synapse Analytics (formally knows as Azure SQL DW)
- Azure Data Explorer (know as ADX)
- AZ HD Insight
- Power BI
- … and many, many more.

- Azure Migrate Documentation
You might be looking at the definition of migration from a different angle, it may have a different meaning like migrating VM, SQL configuration and other on-premises services, take a look at Azure Migrate Appliance under the Azure Migration documentation.
Choose an Azure solution for data transfer.
Check out some of Microsoft’s data transfer solution, in this link (click here) you will find few scenario that can help you to understand the existing data migration approaches.
Conclusion
Migrating to Azure is very simple but needs planning, consistency and basic Azure knowledge. You may have a very successful migration, but you need to make sure that the new features in azure services are been used as needed, and finally Microsoft always has a solution for you.